. What is Scikit-Learn Primarily Used For?
Its primary use cases fall into four main categories:
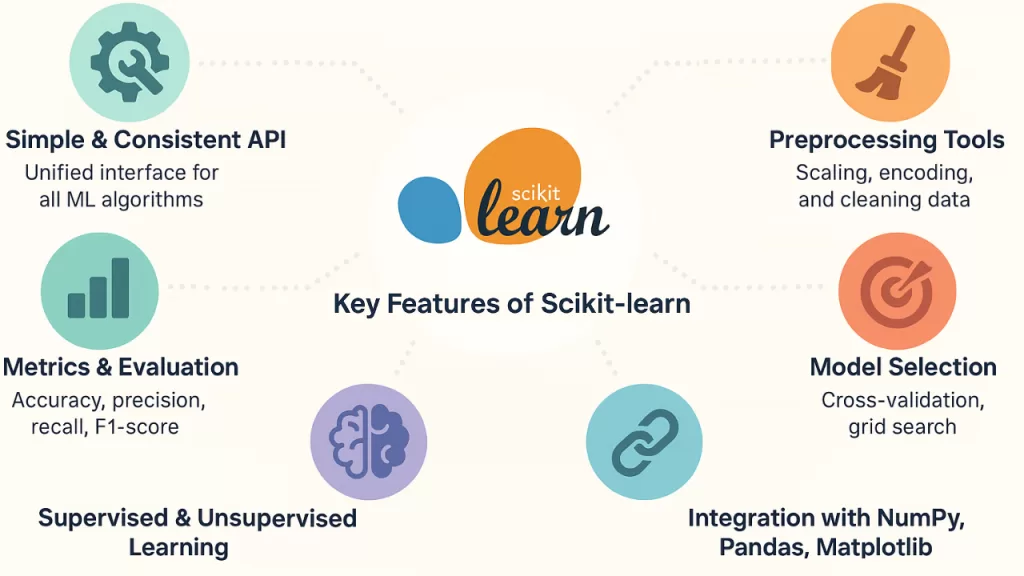
All Core Features and Modules in Detail
A. Supervised Learning Algorithms
These models learn from labeled training data to make predictions about unseen data.
- Linear Models: Simple and fast algorithms like Linear Regression, Logistic Regression, Ridge, and Lasso.
- Tree-Based Models: Decision Trees and powerful “ensemble” methods like Random Forests and Gradient Boosting that combine multiple trees for higher accuracy.
- Support Vector Machines (SVM): Highly effective algorithms for classifying complex, high-dimensional spaces.
- Distance-Based Models: K-Nearest Neighbors (KNN), which classifies data based on the proximity of surrounding data points.
B. Unsupervised Learning Algorithms
These algorithms find hidden patterns in data without using pre-labeled answers.
- Clustering: Algorithms like K-Means, DBSCAN, and Hierarchical clustering group data based on inherent similarities.
- Manifold Learning & Decomposition: Tools like Principal Component Analysis (PCA) and t-SNE reduce complex data down to 2D or 3D for easy visualization without losing critical information.
C. Data Preprocessing & Feature Extraction (sklearn.preprocessing)
Machine learning models require clean, numerical data. Scikit-Learn offers a massive suite of tools to prepare raw data:
- Scaling & Normalization: Tools like
StandardScalerandMinMaxScalerensure all features have the same weight by putting them on a similar scale. - Encoding:
OneHotEncoderandLabelEncoderconvert text categories (e.g., “Red”, “Blue”) into numerical values (e.g., 0, 1). - Imputation:
SimpleImputerandKNNImputerautomatically fill in missing or corrupted data points in your dataset. - Feature Extraction: Converts raw text or images into numerical matrices (e.g.,
CountVectorizerorTfidfVectorizerfor Natural Language Processing).
D. Model Selection and Evaluation (sklearn.model_selection)
Building a model is only half the battle; you must prove it works.
- Data Splitting:
train_test_splitsecurely divides your data into a “training” set to teach the model and a “testing” set to evaluate it. - Cross-Validation: Tests the model on multiple different subsets of the data to ensure it hasn’t just memorized the training set (overfitting).
- Hyperparameter Tuning: Tools like
GridSearchCVandRandomizedSearchCVautomatically test hundreds of different model settings to find the most accurate configuration. - Metrics: A comprehensive suite of scoring tools, including Accuracy, F1-Score, Mean Squared Error (MSE), and Confusion Matrices.
E. Pipelines (sklearn.pipeline)
Tools and Ecosystem
NumPy: The mathematical engine beneath Scikit-Learn. Scikit-Learn models expect data to be structured as fast, multi-dimensional NumPy arrays.
Pandas: The ultimate data manipulation tool. You will almost always use Pandas to load your data (e.g., from a CSV file), clean it, and explore it before passing the Pandas DataFrame into Scikit-Learn.
SciPy: Provides the advanced statistical and mathematical operations that Scikit-Learn’s algorithms rely on under the hood.